
Across all vertical markets, organizations adopt data virtualization as a core part of their IT infrastructure because data is becoming more distributed, more heterogeneous, and larger in volume. The pressures on business to be more competitive are continually growing, so it is more important than ever before to get fast access to relevant data.
The time is right to realize the potential of data virtualization outside of the logical data warehouse. While a powerful and flexible architecture, the logical data warehouse is a bit like a fishbowl, there is a larger world waiting outside of it, including a wide variety of different fishbowls. The time is right to take that first leap into that larger world.
The Logical Architecture Has Evolved
Gartner’s Mark Bayer came up with the term logical data warehouse 10 years ago to describe the need to logically expand existing data warehouse architectures that were supposed to include all enterprise information but didn’t. Since then, terms like “logical data warehouse” and “hybrid architectures” have been widely used to represent the natural evolution of analytical systems, and data virtualization has played an important role in this process.
However, Rick F. van der Lans illustrated in his post “Unifying the Data Warehouse, Data Lake and Data Marketplace,” that data virtualization can act as a “unified data delivery platform” that brings together not only the data warehouse but also data lakes, data marketplaces, streaming data, and any other data delivery system, helping to tear down data silos to support a wider range of use cases.
If we consider the capabilities of data virtualization outlined in the diagram, I think it’s clear how data virtualization can form an important part of the unified data delivery platform described by Rick.
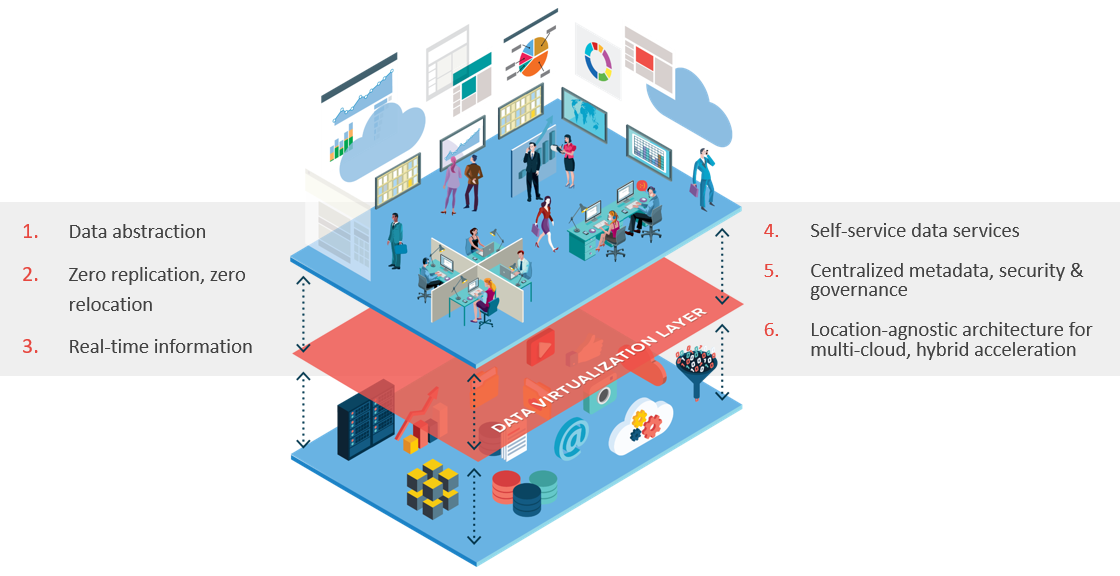
Data Virtualization: A Unified Data Delivery Platform for the Business
Key aspects of data virtualization are its ability to abstract the location and implementation of the data, provide increased speed of data delivery (since data doesn’t need to be replicated) and enable users to consume data in a self-serve manner through the discovery of a published logical data model. Data consumers come to the data virtualization layer to access a common, meaningful model using familiar technologies like SQL or REST, but the data remains in-situ and the data virtualization layer handles the integration of the data on-demand.
This abstraction loosens the coupling of IT and the business, enabling IT stakeholders to work at their own pace to provision data using their most appropriate processing platform, while consumers are provided access to the data wherever it resides through the logical layer. This removes silos and enables consumers to access the data using the applications of their choice, be they reporting tools, data science tools, enterprise applications, or mobile or web apps.
Think Differently: 3 Architectures, one Delivery Platform
Data virtualization therefore forms the backbone of a unified data delivery platform, supporting the modernization of the data landscape behind it.
With this post, I’d like to get you to think differently about data virtualization, so you can imagine where else a unified data delivery platform can add value to your organization. To this end, I’d like to highlight three architectures in which data virtualization can play an increasingly important role.
Enabling Data Service Layers
The first category we’ll look at is the use of data virtualization as a data services layer.
In this scenario, data virtualization publishes certified data services that can be used by any development team, which avoids the problems of project teams creating their own siloed data sets or using non-certified or non-maintained data sources.
With a data services layer, there’s no direct access to the data sources. Consistent data sets are published and made discoverable through the use of data virtualization, which enables any developers, not just BI teams, but developers of operational applications, web portals, back or front office systems, to access and reuse the data.
A good example of the use of a data service layer is Indiana University, a major university in the United States. The university had problems delivering the information senior executives within the university needed to support planning and decision making in a simple, agile, and easy-to-use way.
The university launched a successful data access marketplace that served as a central portal supporting self-service access to the governed and secured data services provided by data virtualization (See the Indiana University Case Study).
Accelerating Cloud Modernization
The second area I’d like to discuss is cloud modernization. The journey for companies looking to modernize their infrastructures by adopting cloud applications and migrating legacy applications to the cloud takes time, and data can become even more fragmented during this process:
- Hybrid architectures develop, with some data still on-premises and some data migrated to the cloud.
- Multi-cloud architectures arise, bringing the challenges of integrating applications across cloud platform providers.
- Maintaining a single point of access and security across the hybrid data architecture is a challenge.
The abstraction capabilities of data virtualization help enable cloud adoption: Data virtualization facilitates the migration of the legacy architecture to the cloud, then the evolution of migrated legacy architecture to more modern cloud analytics platforms (protecting consumers from the changes), enabling users to exploit multiple analytics platforms in the cloud, simplifying access to data in hybrid architectures.
A good example is Asurion, which is a global company that provides device protection insurance and warranty and support services for consumer electronic devices. Asurion wanted to move to the Amazon Web Services (AWS) cloud, so that the company could quickly spin up new data platforms and adopt big data analytics technologies to enable data scientists.
Data virtualization was used to provide a single simplified point of governed, secure access across the data sources in the cloud and on premises (See the Asurion Case Study) enabling the publication of data via a logical model, which reduced the complexity of the consumers’ data environment.
This allowed Asurion to quickly migrate its legacy architecture to AWS and publish data via the data virtualization layer. The company could then move data into a new cloud analytics platform while protecting users from the location change of the underlying data source.
Security rules were complex and had previously been implemented in the legacy siloed data platforms, so there was no way to audit whether these were applied consistently. Acting as a single point of access, data virtualization also enabled Asurion’s authentication policies to be defined in one logical layer.
Facilitating Big Data Adoption
The final area I’d like you to think about is how data virtualization can help organizations in big data adoption, by allowing the data residing in big data platforms to be more easily exploited by consumers:
- Data virtualization makes big data available to users with no big data skills through enabling logical data lakes and the provisioning of an easy-to-access and discover logical model.
- Data virtualization enables the offloading of historic data from expensive data warehouse infrastructure to less expensive storage, e.g. Hadoop, while enabling seamless access to both current and historic data.
- Data virtualization enables the combination of big data with other data to enrich it, e.g., combining predictive analytics output with contextual enterprise data.
- Data virtualization supports data science initiatives by enabling data scientists (as Asurion did) to focus on analytics rather than data integration and the acquisition of the data they need.
An interesting example of the use of data virtualization in predictive analytics comes from a global construction equipment manufacturer. This company wanted to differentiate its products by lowering the total cost of ownership for customers by ensuring that they ran at optimal efficiency with minimum downtime in the field. In the process, the company was able to provide better customer service.
The company has sensors on all its equipment, which send data to be collected in real time to a Hadoop cluster. Predictive analytics algorithms are run across all the sensor data in Hadoop, the goal being to predict when a part needs replacing prior to failing, so that preventative maintenance can be done. This data on its own has little actionable value, but when enriched using data virtualization with contextual information from other systems (parts inventory, maintenance, dealership systems etc.) the analytics add real business value. This enriched data, published through a portal, enables the company to offer a value-added service to customers, enabling them to schedule the maintenance of their plant at the right time to keep production running while maximizing plant uptime and reducing the overall total cost of ownership.
Be the Flying Goldfish; Think Outside of Your Bowl
These three architectures are good examples of data virtualization acting as a unifying data delivery mechanism that facilitates the reuse of certified data, the modernization of IT infrastructure, and the adoption of big data. I hope this post has helped you to start thinking differently about the applications of data virtualization and its possibilities outside the logical data warehouse.

- Data Virtualization: Thinking Outside the Bowl - July 31, 2019
- 3 Pillars of GDPR Compliance - May 9, 2018
- 3 Steps to Data Protection Compliance (GDPR) - May 9, 2017