
Recent studies have shown that data scientists and business users performing self-service data analysis (citizen analysts) spend 80% of their time trying to discover, access, and integrate data.
In other articles, I discussed how data virtualization (DV) plays a key role in removing the burden surrounding data access and integration. In a nutshell, data virtualization provides a unified data integration and delivery layer which acts as the bridge between the IT data management infrastructure and the business users and applications (see Fig. 1). It provides a single entry point to access any data in a secure way, no matter where it is located or its native format. Even more importantly, the DV layer can provide data to each type of user and application in the format that best suits their needs, with almost negligible cost when compared to traditional approaches based on data replication.

Fig. 1
What About Data Discovery?
How can users discover what datasets are available to solve certain information needs? How can they understand the data in those datasets and how to use them?
A typical response to these questions is to build a data catalog, which can be thought of as an enterprise-wide directory of the datasets available for consumption. Note that we are not talking about the type of catalogs built with data governance tools to store a comprehensive inventory of all the IT assets, for data quality and compliance purposes. The catalogs we are dealing with here are “data marketplaces”, where data consumers can go and find data which is ready to use.
A key consideration when building this type of data catalog is that it should be tightly integrated with the platform/s used for the actual data delivery. This is important for several reasons:
- It guarantees the catalog does not provide outdated information. The catalog should show what is available now, without requiring updating information manually or long synchronization processes.
- The catalog should provide access not only to metadata about the available datasets, but also to the actual data. Often, metadata is ambiguous or incomplete, so the best way to know what a dataset offers is querying and searching it. Also, the data may need to be transformed / customized before it can be used for a particular purpose.
- Finally, the platform/s used for the actual data delivery have information about the actual usage of the data set, such as: which users and applications are using it and how often, and which datasets are frequently used together. This information is very important to assess the value of a dataset in the catalog.
Therefore, it’s no surprise that having an unified data delivery infrastructure such as the one provided by data virtualization greatly simplifies creating this type of data catalog. If you have a common platform for providing information to the business, then you can go to a single place to know which datasets are available, how are they being used by other users and applications, and to explore the data they provide. In addition, once you have discovered an interesting dataset, you can get access to it directly through the data virtualization layer without worrying about where it is located or what access protocols the data source natively uses.
Denodo Platform 7.0: What’s New?
Denodo Platform 7.0 provides the two integral functionalities: the unified data integration and delivery layer powered by the leading DV engine in the market (as highlighted by Forrester and Gartner), and a data catalog tightly integrated with it, to allow data discovery for citizen analysts, data scientists and business application developers.
The data catalog included in Denodo Platform 7.0 allows users to see extensive metadata about the available datasets including column descriptions, data lineage and activity indicators on how the dataset is used. In addition, datasets can be classified and browsed in different ways, such as business categories, tags and the relationships with other datasets (see Fig. 2).
Fig. 2
Search functionalities are also available over both the metadata and the actual content. For this, Denodo provides its own indexing and search engine but it is also possible to use ElasticSearch.
The data catalog also provides a second type of functionality, that allow business users to perform the final data transformations and combinations on the datasets to prepare them for personal use. This can be performed with a friendly UI which hides the complexity of the transformation functions and SQL operations working behind the scenes (see Fig. 3).
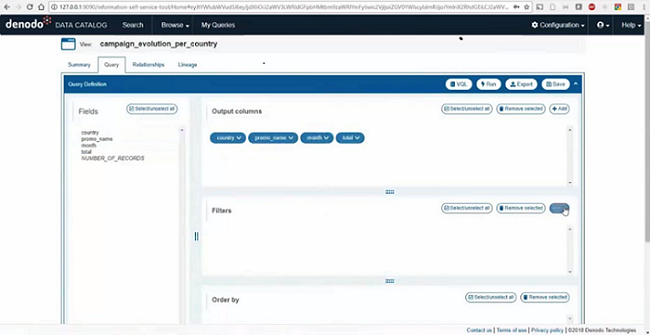
Fig. 3
The data catalog also enables iterative collaboration between IT and citizen analysts to refine the datasets available for consumption.
In summary, Denodo Platform 7.0 is designed to bridge the gap between the IT data infrastructure and the business users and applications. Citizen analysts, data scientists and developers of business applications can discover and access data in a way that they can use effectively, allowing them to focus on deriving insights and generating significant business impact for their companies, without worrying about the complexities of discovering, accessing, transforming and integrating data.
Watch this video to see Denodo Platform 7.0 in action:
You can find more information about Denodo Platform 7.0 here.

- Performance in Logical Architectures and Data Virtualization with the Denodo Platform and Presto MPP - September 28, 2023
- Beware of “Straw Man” Stories: Clearing up Misconceptions about Data Virtualization - November 11, 2021
- Why Data Mesh Needs Data Virtualization - August 19, 2021