
We’ve all heard the common expressions of the form “thing A is the new thing B.” Often spoken in a whimsical tone, this expression is meant to denote that “thing B” is being replaced in usage and popularity by “thing A.” Originating in the fashion design world, this expression is meant to convey that one fashion style is being replaced by another, in terms of popularity. One very commonly known example is “orange is the new black,” as referenced in the aptly named Netflix series about an executive who is forced to trade her black power suits in for orange jumpsuits after having to spend time in a minimum security prison. There is also “40 is the new 30,” used when someone, usually entering a midlife crisis, is trying to accept their new age bracket by implying that 40 years old is now as cool as 30 years old used to be. In a very quirky way, “thing A is the new thing B” is meant to denote a changing of the guard, a new way of doing things, or a new way of perceiving things. In the world of data management technologies, it might also be said that data virtualization (DV) is the new database (DB).
Now before you accuse me of temporary insanity, please know that I am not literally saying that database technology is going to be replaced by data virtualization technology. Databases serve an essential purpose and will certainly never be replaced in this lifetime and possibly the next. However, in a world in which we are gathering data at so much velocity, variety, and volume, the database is now just one of many storage options available for business-critical data. The relational database is an ideal storage fit for many categories of customer use cases but the range of data-driven use cases available today have exceeded the capabilities of a typical relational database. In most large organizations today, data storage options include traditional databases, NoSQL data stores, Hadoop clusters, spreadsheets, delimited files, cloud APIs, and an ever growing list of fit-for-purpose sources of critical business data.
Today’s Typical Business Data Landscape
In analyzing the trajectory of data management technologies over the past few decades, we can see an evolution based on changing business needs. In the 1980s, we saw tremendous growth in the deployment of relational databases as a means of storing and managing master data, transactional data, and the relationships amongst those various entities. As those databases began growing in number, scope, and size, we then saw data being replicated and centralized in large data warehouses beginning in the 1990s. That served its purpose until the variety and complexity of data began to grow from structured data to semi-structured and unstructured data. From spreadsheets to XML documents to JSON documents to CSV files to streaming data from mobile and IoT devices, this increased velocity, volume, and variety of data necessitated the deployment of new data storage mechanisms. In addition to traditional databases and data warehouses, today’s typical data landscape usually includes data stored in NoSQL databases, graph databases, cloud APIs, Hadoop clusters, and data lakes residing in both on-premises data centers and multiple cloud environments. The functionality of each mission-critical business application generally calls for the storage and access of data in repositories that are best suited for that specific application. As a result, various silos of data are created within on-premises data centers and in multiple cloud environments. With this being the nature of the typical business data landscape today, it becomes a significant challenge for business decision makers within data-driven organizations to analyze their breadth of data assets to gain the insight necessary to make timely and informed business decisions.
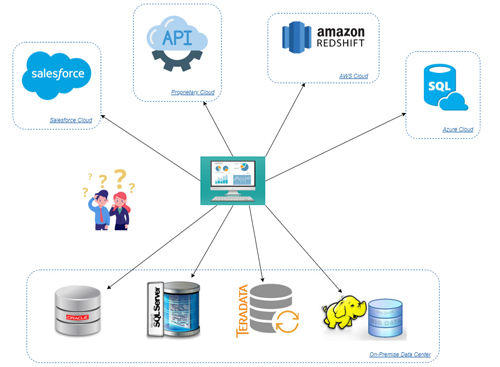
Envision a retail business with customer data in an Oracle database, sales transactions in a SQL Server database, historical sales data in a Teradata data warehouse, web traffic data stored in a Hadoop cluster, CRM data stored within Salesforce, and consumer demographic data accessible via a cloud API. In addition to these data sources, as a result of recent business acquisitions, they also have additional sales data in AWS Redshift and Azure SQL Data Warehouse. The complexity of this hybrid data environment, with data scattered throughout numerous on-premises and cloud data sources, provides a significant obstacle for business leaders trying to gain essential information to make critical, timely decisions. Imagine this company’s director of finance needing to make financial projections for the upcoming year. The inputs for developing this forecasting insight include enterprise-wide historical sales data, customer purchase intent based on past purchases, user web traffic data, and consumer demographic data. For the IT department tasked with providing the data necessary for developing this insight, using a traditional ETL approach would require replicating data from 8 data sources across 5 distinctly different environments into a single environment for further analysis. The complexity of this effort, the financial and human resource-intensive activities involved, the length of time necessary to develop ETL jobs, and the time-consuming execution of the processes necessary to physically migrate data from these disparate environments into a single repository, each represent significant deterrents to being able to make critical business decisions in a timely manner.
Data Virtualization: The New Paradigm
With these increasingly complex data environments, the standard database is simply not enough to empower business users with the information they need to develop critical insights into business operations. We are in the midst of a new era of data-driven innovation where data virtualization has become an essential technological capability to fully empower business users with timely access to information needed to make critical business decisions. Data virtualization enables the highly performant, real-time consumption of data that is distributed across various data sources in multiple environments through a logical centralized point of access, without the need for resource- and time-intensive data replication processes. In the aforementioned hypothetical example of the complex data environment of a retail business, data virtualization would enable the creation of logical data entities representing data from the disparate sources in a logical semantic model. This logical semantic model can then be consumed directly from business intelligence, analytics, and other data consumption applications without necessitating that the disparate data sources be replicated into a single one. This dramatically reduces the time and effort required for providing business decision makers with mission-critical information to make critical business decisions within data-driven organizations.
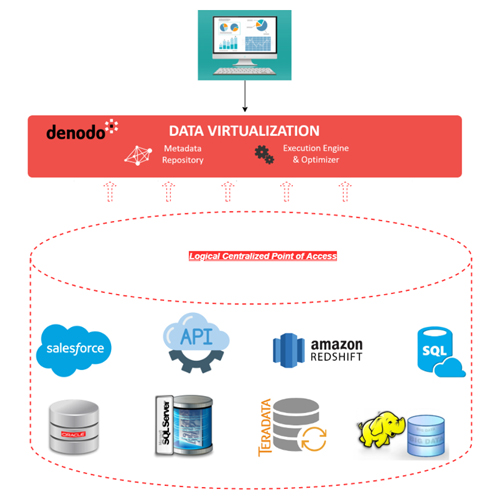
“Data Virtualization is the new Database”
Data lies at the very foundation of much of the innovation that is taking place in industry today. The power of predictive analytics, machine learning, and artificial intelligence technologies that drive so much of today’s innovation is reliant on massive amounts of data that is distributed in very fragmented and highly complex on-premises and cloud data environments. The traditional relational database by itself is insufficient to serve all the needs of today’s data-driven organizations. Data virtualization is a key enabling technology that dramatically improves the capability of business users to analyze distributed data assets and develop critical insight in a timely and efficient manner. By revolutionizing the data access capabilities necessary to power today’s data-driven organizations, it can be said that data virtualization is the new database. To phrase this in a manner more suited for printing on a t-shirt or bumper sticker, “DV is the new DB.”
- Providing the Data Foundation for GenAI Success - January 15, 2025
- How to Shop for Data - January 18, 2024
- Data Fabric and the Transformation of Business - February 8, 2023