
Data lake, by combining the flexibility of object storage with the scalability and agility of cloud platforms, are becoming an increasingly popular choice as an enterprise data repository. Whether you are on Amazon Web Services (AWS) and leverage AWS S3 or Microsoft Azure and you use ADLS as your object storage of choice, the flexibility and openness of data lakes are enabling organizations to store more information and tackle more analytics use cases.
But just because you can ingest and store everything easily doesn’t mean you can manage it effectively and realize value quickly. While data lakes have resolved many previous constraints associated with data storage, they have also brought on new challenges. This is especially true in large enterprises, in which data lakes must work alongside existing data repositories.
At Denodo, we can see the tremendous potential value of data lakes. However, from our customers, we also hear about data lake constraints and limitations.
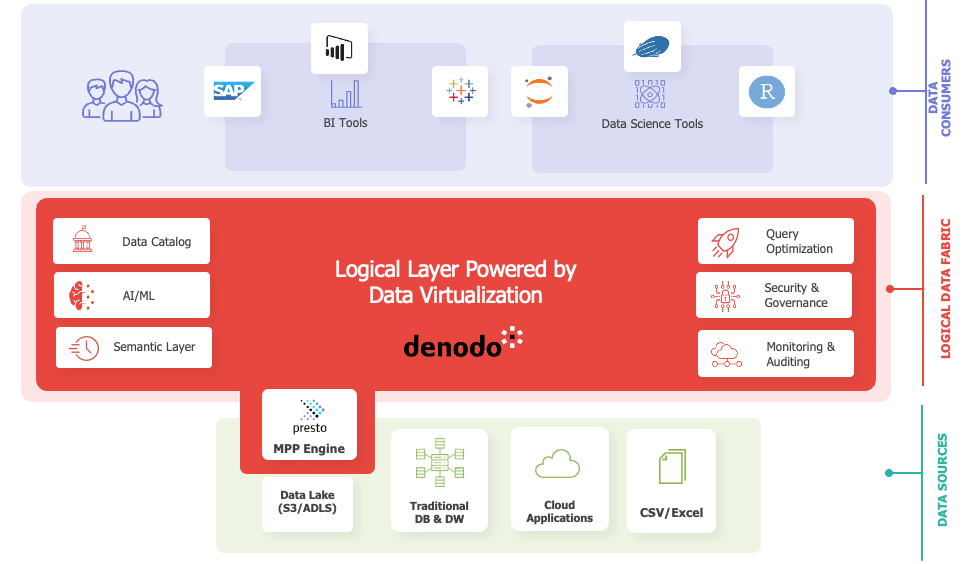
This is why, with the latest release of the Denodo Platform, we are tackling some of these challenges head-on. The premiere new feature of our latest release is an embedded data lake SQL engine that will form an integrated part of the Denodo Platform going forward. By extending our market-leading data management platform with a highly scalable, flexible MPP (massively parallel processing) SQL data lake engine, we believe we can help our customers realize business value faster by providing all the necessary components of a successful data lake strategy.
Fast SQL Access
Data lakes are large repositories of raw, structured, and unstructured data files stored in their native formats. But while they are extremely flexible and scalable, no business value can be realized from the data until it is accessed and used by data consumers. Though data lakes can support different types of workloads, most data lake consumers still focus on analytics workloads and have a strong preference for SQL as the query language. Therefore, having a scalable data lake SQL engine that can support fast, reliable SQL queries on top of the data lake is the first hurdle most organizations must overcome.
This new embedded data lake SQL engine powered by Presto, a next-generation distributed query engine that has overcome some of the shortcomings of previous data lake query engines. Not only is it used in some of the largest companies today, such as Facebook and Twitter, but it is also supported by a strong, vibrant open-source community. We are super-excited to bring the power of Presto to our customers and to contribute to the Presto community.
The new embedded data lake query engine provides consumers with a highly scalable, performant SQL engine with which to access data lake data. We have also added graphical user interface components that make it extremely easy to browse your data lake via introspection and easily register the underlying files without special knowledge or skill.
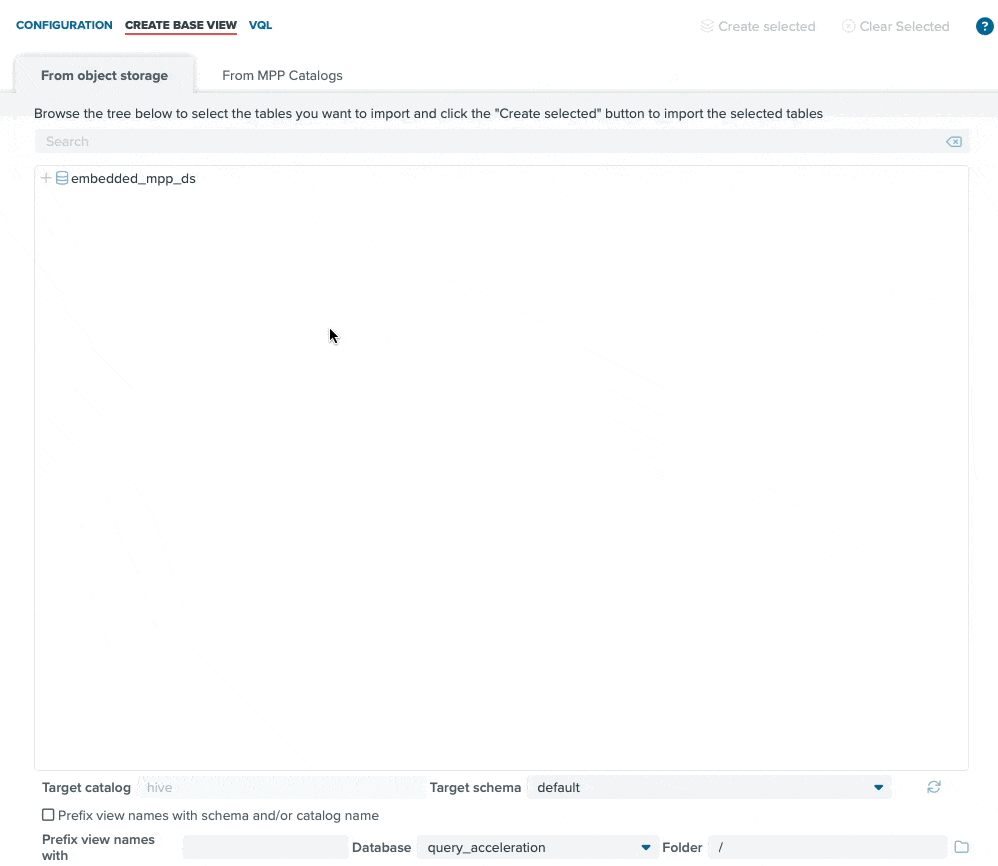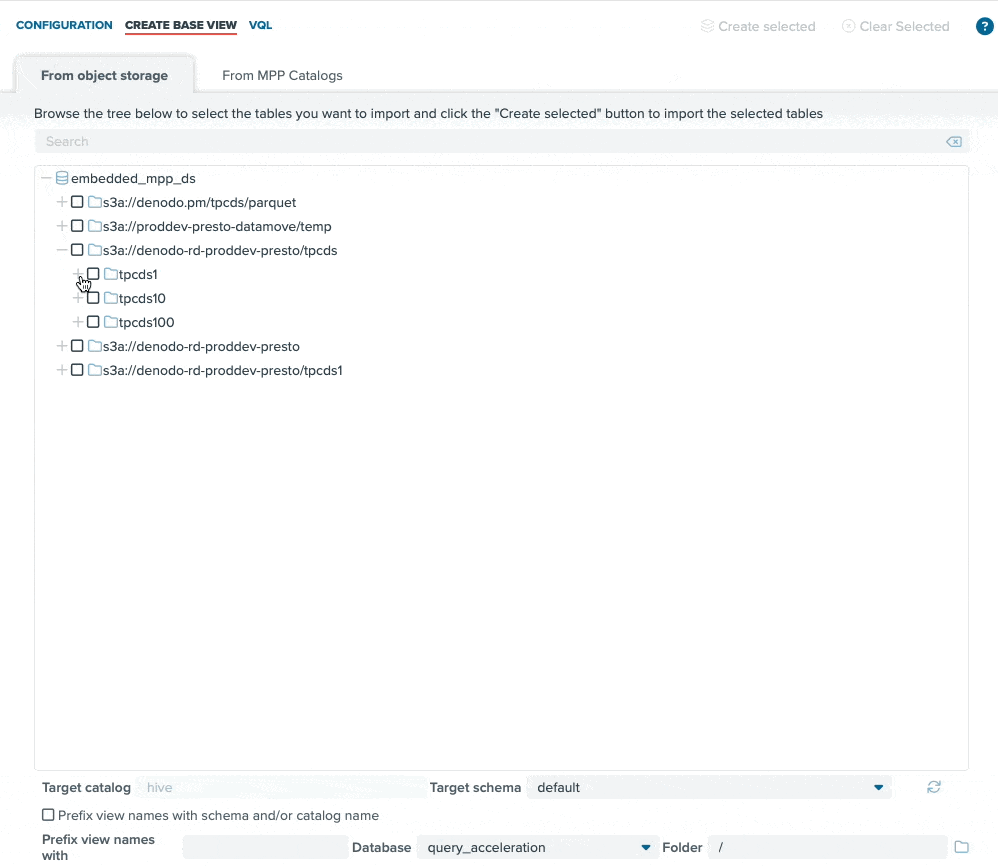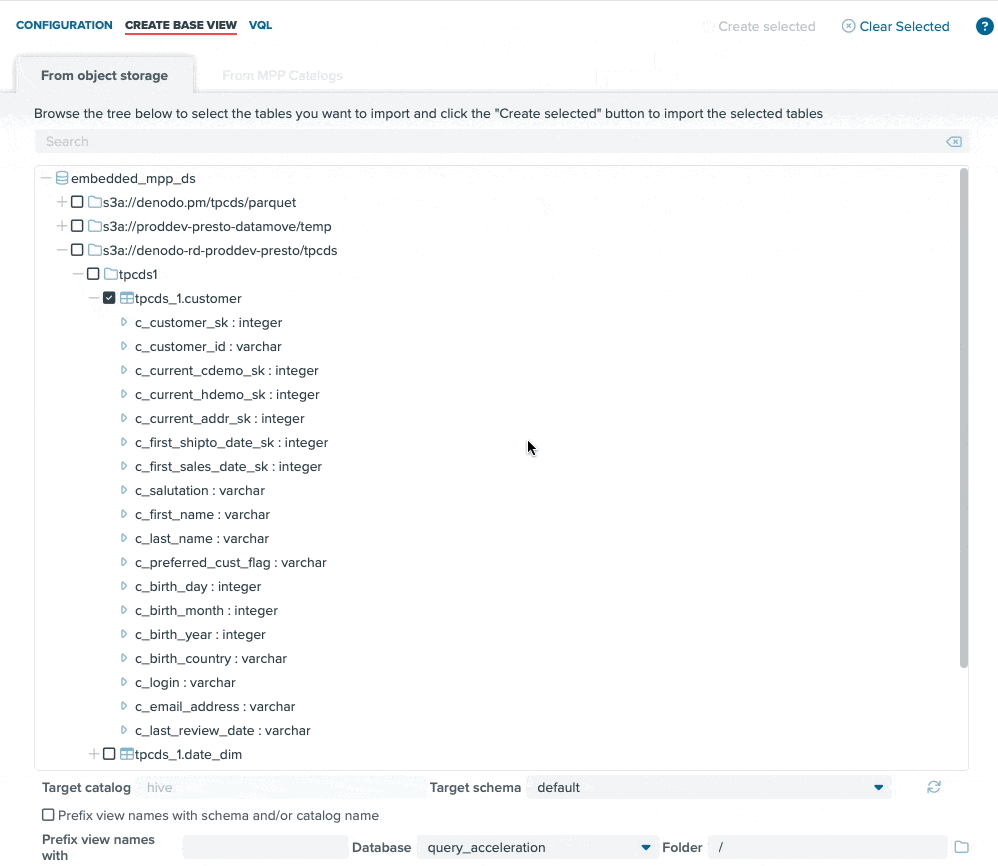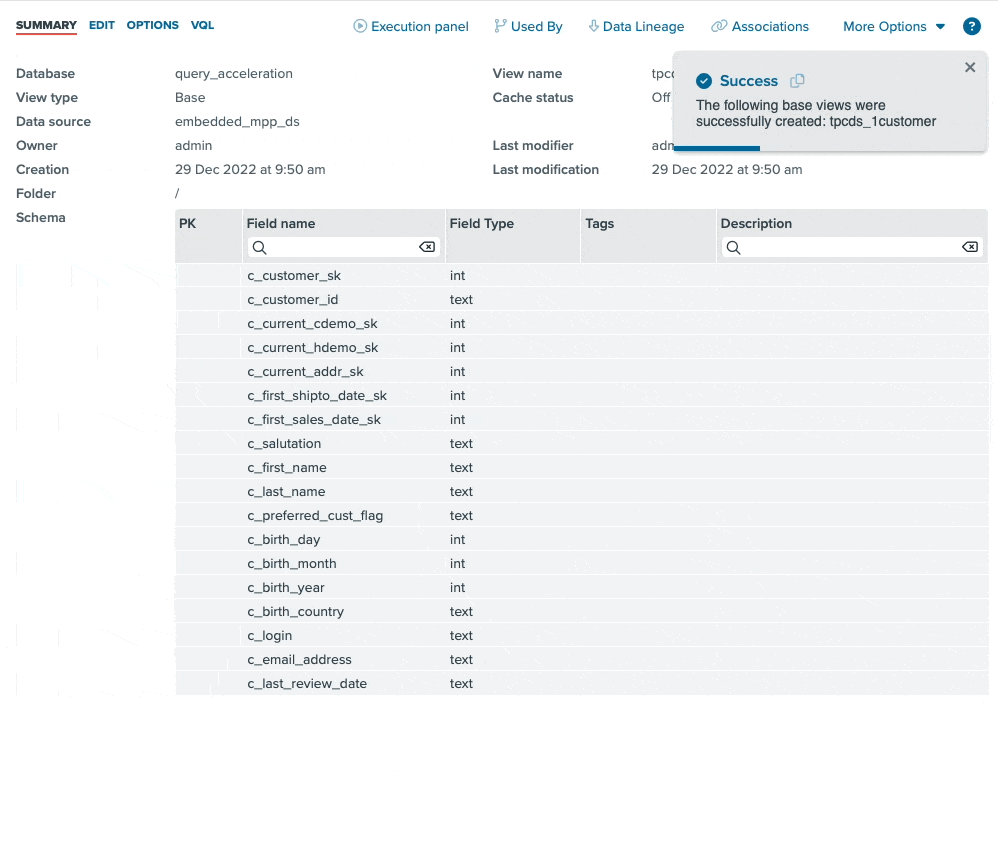
The screen recording above highlights how easy it is to configure a data lake source (AWS S3 in this case), browse through the storage hierarchies (S3 buckets in this case), and register the data lake file (“tpcds_1.customer” in this case) as a structured table view for easy SQL access. The drag-and-drop interface makes this process incredibly straightforward, and the data consumer can be querying data lake files in minutes.
While having an easy-to-use, scalable data lake SQL engine is critically important, it is not nearly enough to ensure adoption and success. What makes Denodo unique is our ability to combine a performant data lake SQL engine with our mature, proven logical data fabric platform. In this way, we are delivering a powerful data lake engine while resolving other shortcomings of data lakes, such as data discovery and collaboration.
Data Discovery and Collaboration
Data lakes (often referred to as “data swamps”) can be big places with lots of useful and not-so-useful data. This is why a robust data discovery capability is so important. The Denodo Data Catalog provides an effective way to search and discover data within a data lake. Not only can consumers find the data they need by browsing semantic objects (categories, tags) or via Google-like search, but the catalog’s built-in artificial intelligence (AI) capabilities can even recommend data lake assets that the user might be interested in.
By streamlining the process of data cataloging and data provisioning, we want to move the focus from collecting data to connecting to and using data lake data. Ultimately, we want to help our customers develop a data marketplace that can easily deliver data products to multiple personas, regardless of whether the underlying data originated from a data lake or a data warehouse. With this latest release of the Denodo Platform, we believe we are one step closer to helping organizations to realize this vision.
Data Lake Integration with Other Enterprise Data Sources
Unless you have all your data stored in a central data lake, it is inevitable that data lake data has to be integrated and managed along with other enterprise data repositories and applications. While your customer’s behavioral data might be stored in the data lake, customer interactions and transaction data are likely to be stored in CRM systems and marketing data marts. The value of these siloed data sources is amplified when they are integrated and connected together.
This is why a logical data fabric needs to form the foundation for a data lake architecture. It enables organizations to connect disparate and siloed data sources easily and quickly. A traditional approach to data management means that you have to build extract, transform, and load (ETL) pipelines to physically replicate data from a data lake into a data warehouse before a user can access an integrated view of the data. A logical approach, leveraging data virtualization provided by the Denodo Platform, can reduce the need for ETL pipelines and create integrated data views in a fraction of the time with much less effort.
Beyond enabling users to easily connect to and integrate data lakes with other data sources, the sophisticated optimization engine offered by Denodo will also ensure that queries are executed as quickly as possible, and that network traffic is minimized. Already an in data virtualization and federated query performance, Denodo has developed new optimization techniques that take full advantage of the embedded data lake SQL engine. This results in even faster query performance and less network traffic across complex, heterogeneous data environments and multiple query scenarios. I can’t wait for customers to experience the power of our new embedded data lake engine and find new ways to connect their data together for new insights.
Security and Governance
Last but certainly not least, we need to deal with the security shortcomings of data lakes. In their raw form, data lake files are very difficult to secure and govern, which makes them a challenge in highly regulated industries. However, by leveraging a platform like the Denodo Platform, organizations can easily implement a wide variety of security measures, such as user access control, data encryption, data masking, and auditing. More advanced capabilities, such as row- and column-based security and tag-based security policy can also be easily implemented on top of data lake data, with minimum effort.
By leveraging a logical data fabric across all data repositories, a single security policy can be used to enforce data security across an entire data estate. The ability to standardize and unify data security implementations across a data lake, data warehouse, and other enterprise applications can be a huge benefit in terms of minimizing implementation efforts and operational risk.
This latest release of the Denodo Platform is the start of a long journey in helping our customers to better leverage their data lake investments. With the Denodo Platform and its newly included data lake SQL engine, we want to ensure that data lakes are accessible, easy to use, and highly secure, all of which are necessary components for a successful data lake strategy.
Get in the Game with Data Lake
Learn more about our latest release and hear directly from our CTO on why we think the combination of a logical data fabric and an embedded data lake SQL engine will be a game changer for our customers.
- Query RAG – A New Way to Ground LLMs with Facts and create Powerful Data Agents - December 16, 2024
- Welcome to the Era of Denodo Assistant - November 20, 2024
- Unlocking the Power of Generative AI: Integrating Large Language Models and Organizational Knowledge - February 22, 2024