
GenAI is driving all kinds of innovations and new ways of working, and we have discovered that large language models (LLMs) are capable of some pretty amazing feats. In my last post I discussed how they can enable users to query the enterprise using a data fabric, to establish some guardrails. In this post, I will discuss how data fabric, combined with semantic indexing, can provide better searching of all kinds of corporate data, as well as summaries of the results, to simplify content.
What is Semantic Indexing?
We have enjoyed the ability to use natural language with search engines for decades. We all have also experienced challenges in choosing the right words to achieve the results we desire. Semantic indexing represents a paradigm shift from keyword-based searches, which merely skim the surface of data repositories. Unlike its predecessor, semantic indexing delves into the underlying meanings and relationships within the data. It seeks to interpret the intent behind user queries, making it possible to retrieve more relevant, related information. This is accomplished by embedding rich context into semantic definitions, with similarities between different words mapped by vectors and represented by points in space, in such a way that the points representing similar content are positioned more closely together. When you use such vectors for searching, search systems look for points that are close, so you get results that are more in line with your expectations, despite your exact choice of words. It really is quite a cool technique.
Why is Semantic Indexing Important?
Since GenAI has piqued our interest by making AI more accessible, organizations have been trying to figure out how to implement it meaningfully and safely. It is well understood that LLMs can sometimes provide questionable responses, so we need ways to reduce that risk. We also know that LLMs do not have up-to-date information or know anything about specific organizations, and that, as I discussed in my first post in this series, retrieval augmented generation (RAG), supported by data fabric, provides a way to bridge this gap. It is pretty well documented that if you provide enough good information to LLMs, you can get some pretty good results. This is why RAG, and subsequently semantic search, have become not only more popular, but necessary. When you access an application that uses RAG to talk to an LLM, it will first try to find relevant information based on your request. The response now provides enough content to make the LLM more capable of responding to meet your expectations—reducing hallucinations.
Requirements for Effective Semantic Indexing
To implement semantic indexing, organizations need to leverage a few different technology components to store the embedding information and index it for fast retrieval, and these components are readily available via open-source and cloud providers. Organizations typically store the embedding information in a vector database, where it is also indexed. To find similar or related information, systems that implement semantic searching take the search terms and look for text representations in the vector database that are close to it. They can then feed those results to an LLM to get meaningful insight. This embedding information, which is comprised of numerical representations, can be applied to images, database schemas, documents, enterprise data, and more.
Data Fabric and Semantic Indexing
Data fabric, as I mentioned in my last post, provides a consistent SQL interface for real-time access across disparate data sources, and is built on the principles of logical data management, which provides access to diverse data sources through a single, logical, governed layer. Data fabric enables the creation of sophisticated services that can, for example, facilitate the feeding and embedding of semantic indices with fresh data, or provide a consistent representation of corporate data for proper indexing. A data fabric can also help control what gets embedded and subsequently indexed. Since vector databases store the embedding information for text and not necessarily the actual text, you can leverage a data fabric to provide secured access to the data behind the embeddings.
An Example Scenario
In my previous post, I described an example application that enabled account representatives to use natural language to query a data fabric directly. For this example, I’m going to take it a step further. The account representatives absolutely love the functionality we gave them in that scenario. In fact, they loved it so much that they now want to be able to find patterns between which products customers ordered and where they were delivered. This would require two searches, one for orders, and one for deliveries.
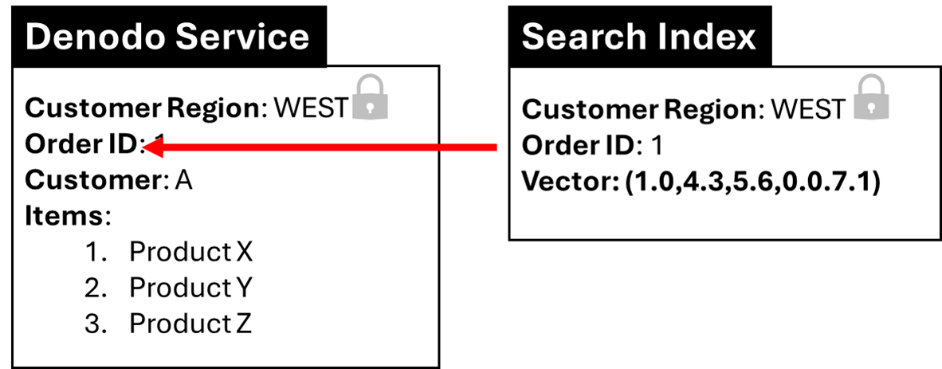
However, since we implemented a data fabric, we decided that we can leverage views of the data and provide structured REST services for orders and deliveries. These services would provide us with a level of control over what we embed and what we expose. Our services can provide access to entire orders and deliveries. When we embed them, we get vectors for all our orders and deliveries—a series of numbers. We only need these embedding vectors to facilitate semantic searching, so we do not need to store the complete orders and deliveries in our database. In the diagram, I have depicted the information in the Denodo Service and the information stored in the Search Index. All we need to store with the vectors is the id and the customer region for each order and delivery. This way, when we search, we only get back ids and customer regions.
Now, the account representatives can search products, customers, and other attributes associated with these entities, and the semantic search will provide relevant results. Since only the unique IDs and customer regions were returned on the first pass, we can now leverage the data fabric to return the details based on the access of the user asking.
We can also use semantic search to enhance our application that converts natural language to SQL. We can embed and index the metadata for our application database and use semantic search to limit that information we need to execute queries. So now, when a user asks a question, we can first perform a semantic search to retrieve the relevant schemas so we can send less information to the LLM.
The Value in Leveraging a Logical Data Fabric
We still achieve all the benefits I shared in my previous blog. We decouple the management of the data from the application. This includes security, performance, semantics, and all related benefits we have shared. We can extend our application to indexing the information and subsequently search and leverage our security model to ensure that only authorized users have access. The Denodo Platform empowers you to make this information available in the ubiquitous protocols and formats supported by semantic search engines. Now you can easily bring semantic searching capabilities to your enterprise.
Summing it Up
Semantic search is becoming a strategic asset for organizations, and integrating transactional data, such as orders and deliveries in the example above, to enhance enterprise-wide searches, is a valuable extension. Logical data management solutions like the Denodo Platform facilitate the integration, structuring, securing, and utilization of information, accelerating delivery, reuse, and improvements. This enables organizations to empower AI applications and semantic search with advanced capabilities.
In my next post, I’ll explore how data fabric, coupled with RAG-enabled GenAI applications, can foster the development of intelligent autonomous agents.
- Data Management with the User Experience in Mind - January 8, 2025
- How Do You Know When You’re Ready for AI? - November 28, 2024
- A Deep Dive into Harnessing Generative AI with Data Fabric and RAG - September 26, 2024