
The emergence of Large Language Models (LLMs) and Generative AI marks a significant leap in technology, promising to deliver transformational automation and innovation across diverse industries and use cases. Having said that, as everyone races to develop next generation AI applications, they are just as quickly coming up against new challenges and hurdles. This is because while LLMs are extremely powerful and capable, they also have inherent limitations and weaknesses today when being adopted in the enterprise context.
One key limitation is that LLMs are only as intelligent as the data they are trained on, and for most organizations today, that means LLMs know nothing about the organizations that they need to help and serve.
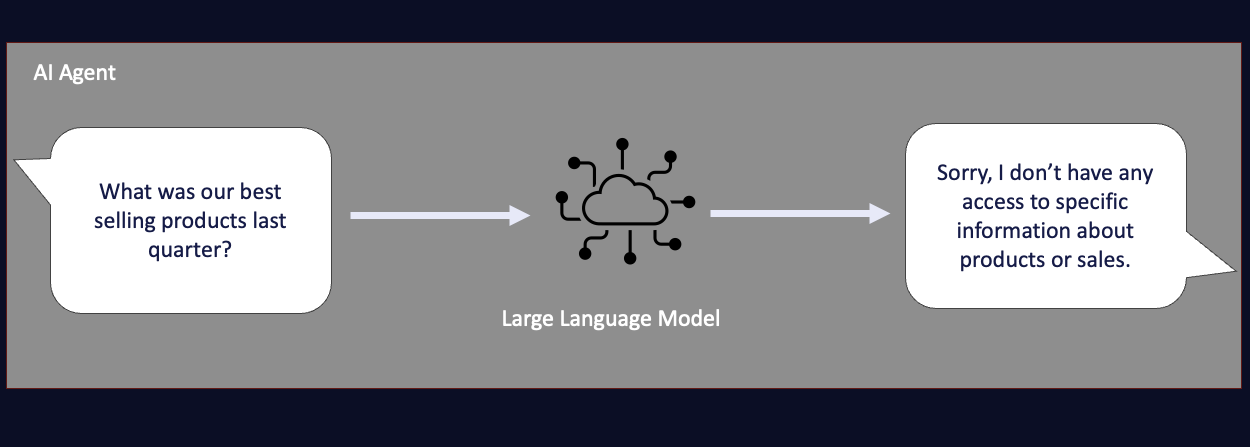
While LLMs have encyclopedia knowledge of historical events and all the literature ever written, they sadly know nothing about your organization without additional efforts or integration. The LLMs know nothing about your customers, nothing about your products, and certainly nothing about your employees. The challenge then becomes how we inject that knowledge into these next-generation GenAI applications, empowering them with the information they need.
Augmentation: The Key to Empowering Generative AI
While it is possible to train and fine-tune existing foundational models with additional information and make them aware of corporate data and information, this path often leads to more complexity and challenges. Not only are the cost and skills required to re-train LLMs prohibitive for most organizations, but the ongoing need to make LLMs aware of the latest data and information makes the iterative process of re-training LLMs constantly simply impractical today. Furthermore, training LLMs with corporate information (that is potentially sensitive) in order to embed that knowledge into the model itself is also fraught with danger, as there is always the risk of data leaks during future interactions. After all, we still know precious little about how LLMs work and how to prevent such data leaks today.
Fortunately, an emerging implementation pattern promises to overcome the limitations of LLM and deliver the knowledge that it needs within an enterprise context in a safe and effective way. Retrieval Augment Generation (RAG) architecture was first discussed in a paper by Meta back in 2020 but is quickly becoming the preferred method to augment LLMs with additional data and information in a cost-effective and secure manner.
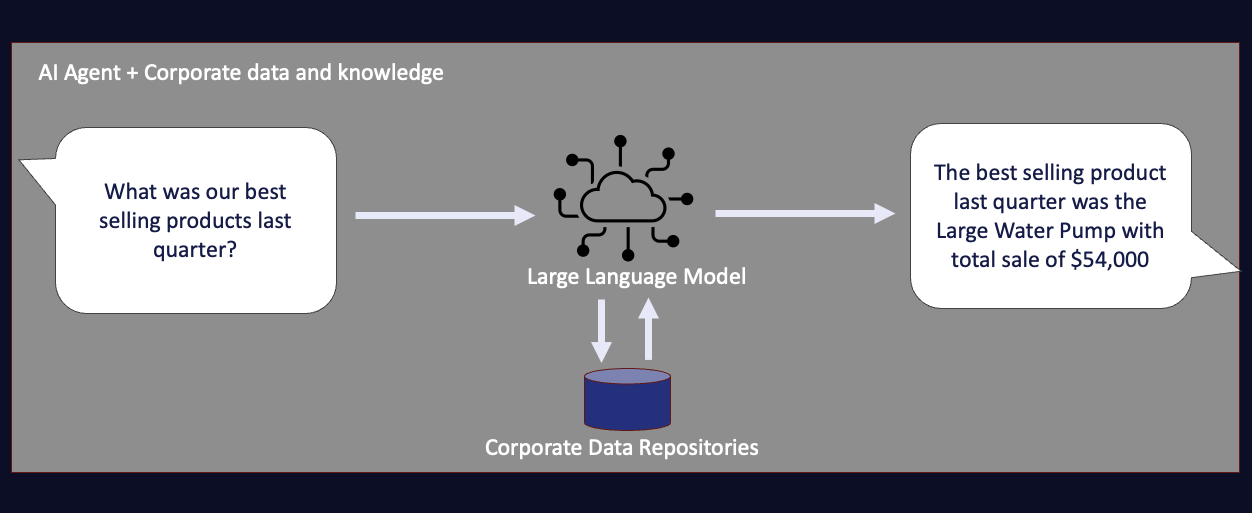
While data in traditional machine learning use cases have played a critical role in the upfront training process, Generative AI and RAG are changing that paradigm and require data to play the role of the knowledge augmentation layer during the inference process. Instead of infusing knowledge into the LLMs by re-training the model, RAG architecture involves adding knowledge through additional context windows during the prompting process. The LLM can then use the additional context provided to generate the necessary response without that knowledge being embedded in the LLM itself.
This simple approach can be applied to structured and unstructured information and is a more agile, cost-effective, and safer (in terms of data leak) way to provide LLMs with additional knowledge and information. Coupled with the powerful code (such as SQL) generation capabilities of LLMs, next-generation AI applications using RAG can open up new types of powerful user interactions and new ways for organizations to unleash the value of their data. That is, if you have the necessary data management foundation to implement RAG within an enterprise context.
While you can now find plenty of simple GitHub projects demonstrating RAG’s power against a single table in a desktop setup, implementing the RAG architecture in an enterprise context against real production data across an often siloed and complex enterprise data landscape can be a nightmare. As we explore tighter integration between LLM and enterprise repositories, we will inevitably encounter the same data management challenges in terms of overcoming data silos, dealing with diverse data source types, and managing complex and lengthy data delivery pipelines.
We believe organizations must evolve and re-imagine data management as the stakes have never been higher. Organizations must act now to build the necessary data management foundation in order to prepare for a new AI-driven competitive landscape that is rapidly approaching us all.
Data Management Foundation for GenAI Applications
A unified data access layer has always been critical to deliver business insights and drive business success. But next-generation AI applications will make it even more important for organizations to take full advantage of the data at their disposal regardless of where it is stored and what form it is in. As LLMs and GenAI technology inevitably evolve, organizations will also require a data management foundation that is flexible and agile, allowing new data sources to be added quickly and new data views to be developed easily to support new emerging AI use cases. A flexible and adaptable data management layer also maximizes your ability to interchange off-the-shelf AI services as new, better, and cheaper options are released.
A semantic layer within this data management foundation provides rich and powerful context against structured data views. This ensures AI applications can find the appropriate data views (using technologies such as Embeddings and Vector Database) and will also ensure that the LLMs have access to the data they need in the form they need. A logical data layer with a rich semantic layer can minimize the complexity of the underlying database technologies and querying protocols and can dramatically simplify the development of LLM powered AI applications.
As the access and query engine for AI applications, the data management foundation of the future will need to deliver scalable, performant, and optimized access to all data repositories. This means a deep understanding of the performance characteristics and constraints of the underlying database and data lake technologies, areas where LLMs lack expertise today. While LLMs have tremendous ability in generating SQL code and analyzing structured data, they are not and were never trained to be a query optimization engine. GenAI application will require a data management layer that it can rely on to query all data repositories in the most performant way via mature and proven optimization techniques.
Finally, it should be no surprise that we must raise the bar even higher regarding data governance and data security requirements when developing Generative AI apps. With the threat of LLM/prompt hacking and data leaks very real, we will need a data management layer to monitor, report, and secure data access constantly and effectively. We will need a global security policy engine that defines and enforces how AI applications can use data in a dynamic and scalable way.
Logical Data Fabric – A Gateway to Integrated Data for AI
When you review the data management considerations needed to power the next-generation AI applications, We believe the logical data fabric stands out as a critical enabler in powering next-generation AI applications.
The Denodo Platform, leveraging data virtualization technology, eliminates the need for data movement or consolidation before augmenting an AI application. It provides a single, consolidated gateway for AI applications to access integrated data and offers a number of other key benefits, including:
- A unified, secure access point for LLM to interact with and query all enterprise data (ERP, Operational Data Mart, EDW, Application APIs)
- A rich semantic layer. Providing LLMs with the needed business context and knowledge (such as table descriptions, business definitions, categories/tags, and sample values)
- Quick delivery of logical data views that are de-coupled and abstracted from the underlying technical data views (which can be difficult to use by LLMs)
- Delivery of LLM friendly wide logical table views without needing to combine multiple datasets first physically
- Built-in query optimization relieves LLMs from dealing with specific data source constraints or optimized join strategies.
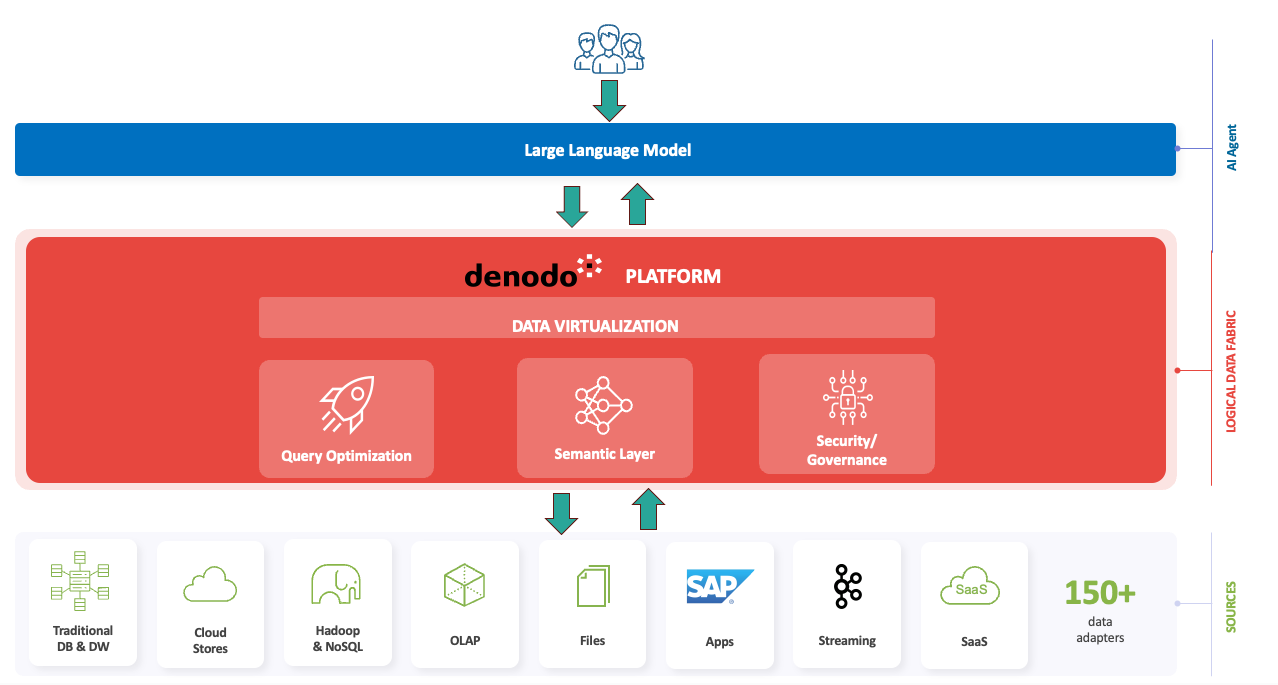
We firmly believe that Denodo and the logical data fabric can become the serving layer for one of the most critical components of generative Al application – your data. The combination of LLMs and logical data fabric can significantly accelerate the development of powerful AI agents.
The journey to harnessing the full potential of LLM-powered AI agents is ongoing and requires continued technological advancements and innovations by the industry as a whole. At Denodo, we are at the forefront, evolving our offerings to meet the demands of an AI-enabled future. Specifically, we are including additional support for technologies such as Embeddings, and Vector Database to further simplify the use of RAG with Denodo. We believe these capabilities will help deliver the necessary data management foundation our customers need now and into the future.
Preparing for a Generative AI enabled Future
In an era of easily accessible LLMs where everyone is using the same foundational models, it is your data that will give you a competitive advantage. From that perspective, nothing has really changed. What has changed is how you need to think about data management in order to unleash the full potential of generative AI capabilities.
As we stand on the brink of a Generative AI enabled future, it’s crucial to ask: Do you have the necessary data architecture and data management foundation to not only leverage GenAI effectively but also build a sustainable and lasting competitive edge.
- Query RAG – A New Way to Ground LLMs with Facts and create Powerful Data Agents - December 16, 2024
- Welcome to the Era of Denodo Assistant - November 20, 2024
- Unlocking the Power of Generative AI: Integrating Large Language Models and Organizational Knowledge - February 22, 2024